One of the common practice to improve performance of Hive queries is partitioning. Partitions are simply parts of data separated by one or more fields. Creating a partitioned table is simple:
CREATE TABLE events (
created TIMESTAMP,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING
) PARTITION BY (
year INT,
month INT,
day INT,
hour INT,
country STRING
)On HDFS will be created next folder structure:
/user/hive/warehouse/default.db/events/year=2018/month=1/day=1/hour=1/country=BrazilSo every time when we will use partitioned fields in queries Hive will know exactly in what folders search data. It can significantly speedup execution because instead of full scan Hive engine will use only part of data.
Win? No. We have another problem — there are a lot of recommendations to limit amount of partitions in about 10000. Lets calculate how much partitions could have our table per one year:
1 year * 12 months * 30 days * 24 hours * 100 countries = 864000 partitions.About 1MM partitions is much more than recommended 10K! Ok, we can remove country from partitioning and it will get us 8640 partitions per year — much better. But what if we require data for 2,3,5,10 years? We can again remove by hour partitioning but our queries became slower or may be we load data by hour and sometimes need to reload some hours. Solution is simple — keep our partitioning structure as is. Hive can efficiently work even with 1MM partitions but with some reservations.
Let’s review Hive architecture.
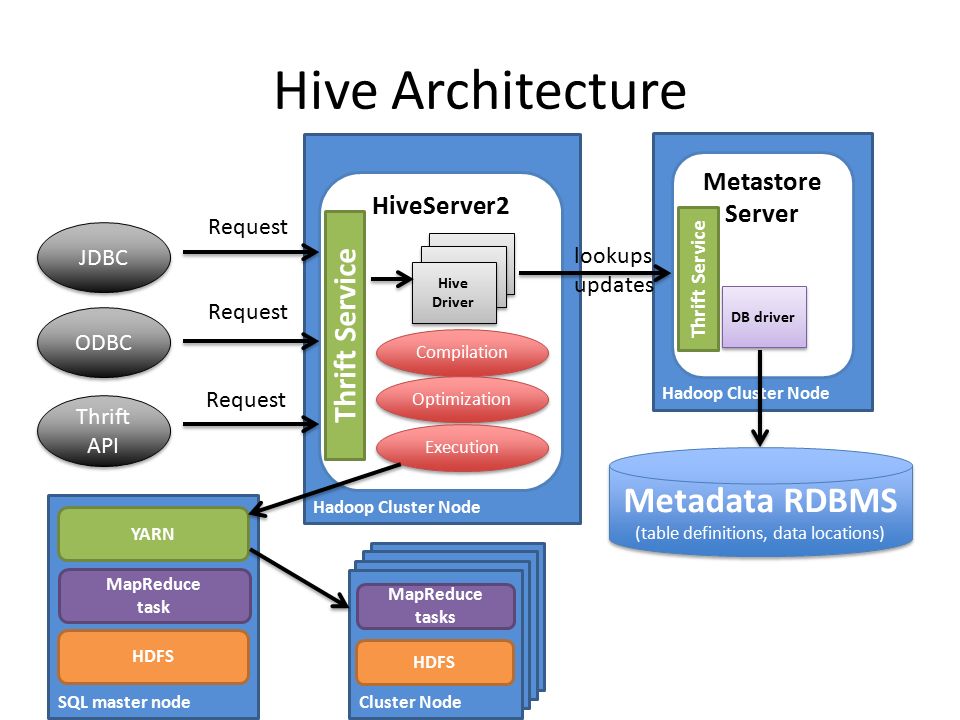
What main parts do we have here:
- HiveServer parse sql query, do query optimizations, request table’s metadata from Metastore Server, execute query (MR2, Spark, Tez).
- Metastore manage all metadata: tables structure, partitions and etc. As backend storage using relational database. By default Hive uses built-in Derby server but it can (and must for production use) be reconfiguring to MySQL or PostgreSQL.
Spark implement his own SQL Thrift Server and interacts with Metastore (Schema Catalog in term of Spark) directly.
When HiveServer build execution plan on partitioned table it request data about available partitions and have two methods for it:
- listPartitions — return all partitions for table. As we already know partitions are stored in database. And if we have a lot of entries at can take considerable time to retrieve all of them. It will decrease total performance and even cause to errors like:
java.net. SocketTimeoutException: Read timed out - listPartitionsByFilter — try to pushdown some of the filters to relational storage.
That’s mean when you write query like
select * from events where year=2018 the filter part related to partitioned columns will used by Metastore Server to get only required data:
select "PARTITIONS"."PART_ID" from "PARTITIONS"
inner join "TBLS"
on "PARTITIONS"."TBL_ID" = "TBLS"."TBL_ID" and "TBLS"."TBL_NAME" = 'events'
inner join "DBS"
on "TBLS"."DB_ID" = "DBS"."DB_ID" and "DBS"."NAME" = 'default'
inner join "PARTITION_KEY_VALS" "FILTER1"
on "FILTER1"."PART_ID" = "PARTITIONS"."PART_ID" and "FILTER1"."INTEGER_IDX" = 1
where ("FILTER1"."PART_KEY_VAL" = '2018')So to have fast queries we need to be sure listPartitionsByFilter method is used. To support it for Spark spark.sql.hive.metastorePartitionPruning option must be enabled.
By default Hive Metastore try to pushdown all String columns. The problem with other types is how partition values stored in RDBMS — as it can be seen in query above they are stored as string values. So trying to pushdown filter like year > 2018 will return wrong result. Fortunately there is a configuration property hive.metastore.integral.jdo.pushdown (false by default) for Hive Metastore which turn on partial support for integral types. Partial mean it will support only few logical operations: equals and not equals.
/**
* @return true iff filter pushdown for this operator can be done for integral types.
*/
public boolean canJdoUseStringsWithIntegral() {
return (operator == Operator.EQUALS)
|| (operator == Operator.NOTEQUALS)
|| (operator == Operator.NOTEQUALS2);
}Does it mean filters like year between 2015 and 2018 will not pushdown? Not really — it depends on SQL optimisation engine. For example Spark prior 2.0 doesn’t support such optimizations and will work only with '=', '!=', '<>' operations. But latest versions do this job well and will transform it to year=2015 or year=2016 or year=2017 or year=2018. Even filter like year(from_unixtime(created)) > 2015 on Spark 2.x will be processed correctly.
To make sure that everything works correctly you can set INFO level logs for Hive Metastore and search lines like:
[INFO] org.apache.hadoop.hive.ql.log.PerfLogger: </PERFLOG method=get_partitions_by_filterAte logo!
This post is also available in: Английский
1 комментарий к “How to work with Hive tables with a lot of partitions from Spark”